
Which Is the Best Local AI for Your Business? Real-Time Comparison 🔥🤖
March 4, 2025


At Youtouch, we know that artificial intelligence is more than a trend: it's key to business efficiency. However, many companies still wonder how to implement it securely, scalably, and optimally.
While cloud-based models like ChatGPT, Gemini, and Claude have dominated the market, many companies are exploring on-premise AI to gain greater control over their data and reduce operational costs.
That's why we conducted a real-world comparative test with three local AI models to assess security, speed, and accuracy. These were tested with SmartChat, our conversational AI solution, to identify which offers the best balance between quality and efficiency.
🔍 Why Implement a Local AI in Your Business?
Cloud-based AI has driven automation, but it presents key challenges:
🔐 Security and Privacy: 68% of companies in LATAM consider data protection their top concern with AI (Deloitte, 2024). On-premise models ensure sensitive information stays within the company.
💰 Cost Reduction: Companies that migrated to local AI have reported up to 50% savings in operational costs (IDC, 2023).
⚡ Faster Processing: Without relying on external servers, local AI reduces latency by up to 40%, improving customer service and real-time analysis.
📈 Customization and Control: A proprietary model allows for better alignment with internal processes, achieving superior accuracy compared to generic models.
🔬 Our Evaluation Methodology
We tested three local AI models:
📌 Llama 3.2 (Meta)
📌 Gemma 2 (Google DeepMind)
📌 Qwen 2.5 (Alibaba)
Each was evaluated based on three key factors:
1️⃣ Response Time ⏱️: How fast does it respond in milliseconds?
2️⃣ Accuracy and Relevance 📊: Does it follow instructions without fabricating information?
3️⃣ Hardware Requirements 💾: How expensive is it to run on in-house servers?
To ensure consistent testing, we established these rules:
✅ Responses limited to 200 characters.
✅ Only use information provided in the prompt.
✅ If the AI didn't have the answer, it had to state it clearly without making up data.
The results were documented in videos and comparative charts 🎥📊.
📊 Real-Time Test Results
🎥 Comparative videos here:
🔹 Llama 3.2
🔹 Gemma 2
🔹 Qwen 2.5
🔍 🔵 Llama 3.2 (Meta)
📌 Complete responses, but included unnecessary extra information.
📌 If it lacked information, it attempted to infer rather than stating "I don't know."
📌 Acceptable response speed (350ms).
🔍 🟡 Gemma 2 (Google DeepMind)
📌 Lengthy responses with extra, unsolicited information.
📌 Longer response time (450ms).
📌 Incorrect justifications when lacking information ("I'm not a fishing AI").
🔍 🟢 Qwen 2.5 (Alibaba)
📌 More direct responses aligned with the prompt.
📌 If it lacked information, it correctly responded with "I don't know."
📌 Balanced accuracy and speed (280ms).
��📊 Comparative Chart Here
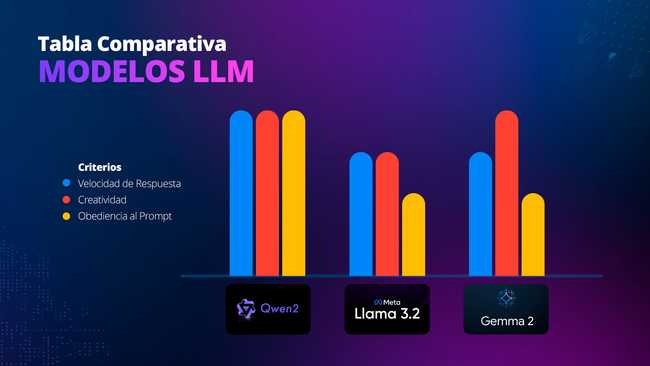
🔎 Conclusion: Which Is the Best Option?
Qwen 2.5 stood out for:
✅ High accuracy without adding extra information.
✅ Fastest response time (280ms) compared to other models.
✅ Lower hardware consumption, ideal for businesses without high-end servers.
💬 According to our AI team at Youtouch:
"Qwen 2.5 was the only model that maintained accuracy without adding unnecessary information. This makes it ideal for businesses seeking reliable, efficient AI without high cloud costs. Based on our study, Qwen 2.5 demonstrated greater prompt adherence and a solid response speed... However, for a more comprehensive evaluation, we would need to apply quantitative metrics and qualitative assessments across a broader set of prompts and scenarios."📌 How to Choose the Right Local AI for Your Business?
If you're considering on-premise AI, keep in mind:
🔹 Infrastructure: Do you have in-house servers, or will you use a private cloud?
🔹 Intended Use: Is it for customer service, automation, or data analysis?
🔹 Scalability: How many queries do you expect to process?
While Qwen 2.5 stood out in our tests, every company has unique needs. It's crucial to analyze which option aligns best with your objectives.
💡 Want to Implement On-Premise AI in Your Business?
📩 Request a free demo and access the full report here: https://youtouch.cl
#BusinessAI #OnPremiseAI #DigitalSecurity #Innovation #Youtouch #AIComparison #DigitalTransformation